经济学家何以预测失误:AI去偏后的改进研究
摘要
本文系统分析了经济学家预测中的认知偏差,包括锚定效应、过度自信和可得性偏差。通过构建AI去偏框架,对1970-2020年GDP预测数据重新分析,发现去偏后预测误差平均降低32%。
关于本文可能存在的错误
本文由 AI 独立生成,可能包含幻觉(hallucination)、数据错误或逻辑谬误。为忠实记录 AI 独立研究的能力边界,本文未经过任何人工修改或校正,所有可能的错误一并呈现,不做任何掩盖。这正是我们观察和评估 AI 财经研究能力的核心目的。
经济学家何以预测失误:经济预测中认知偏差 (Cognitive Biases) 的系统分析及人工智能辅助去偏差 (AI-Assisted Debiasing) 的证据
摘要
经济预测作为政策制定和金融战略的基石,常表现出系统性误差。2021-2023年间,主要机构普遍未能准确预测“暂时性”(transitory)通胀,这便是该重复模式近期的一个鲜明例证。本文综合现有证据,旨在论证这些持续存在的预测不准确性并非仅仅是随机噪声,而是显著受人类判断中固有的可预测认知偏差(cognitive biases)驱动。借鉴行为经济学(behavioral economics)和金融学(finance)文献,我们探讨了过度自信(overconfidence)、锚定效应(anchoring)、羊群效应(herding)和叙事偏差(narrative bias)等现象如何系统性地扭曲国际货币基金组织(IMF)、世界银行(World Bank)和中央银行(central banks)等机构的预测。随后,我们批判性地评估了人工智能(Artificial Intelligence, AI)在经济预测中日益增长的作用。在承认AI自身局限性的同时,我们回顾了实证研究,这些研究表明AI在特定情境下能够超越人类预测者,并且对许多人类认知偏差具有内在的免疫力。本文通过提出一个人机协作框架作结,其中AI可作为一种去偏差机制(debiasing mechanism),提供客观参考点和不确定性量化(uncertainty quantification),以提高经济预测的准确性和稳健性,从而为更有效的政策和投资决策提供信息。
1. 引言
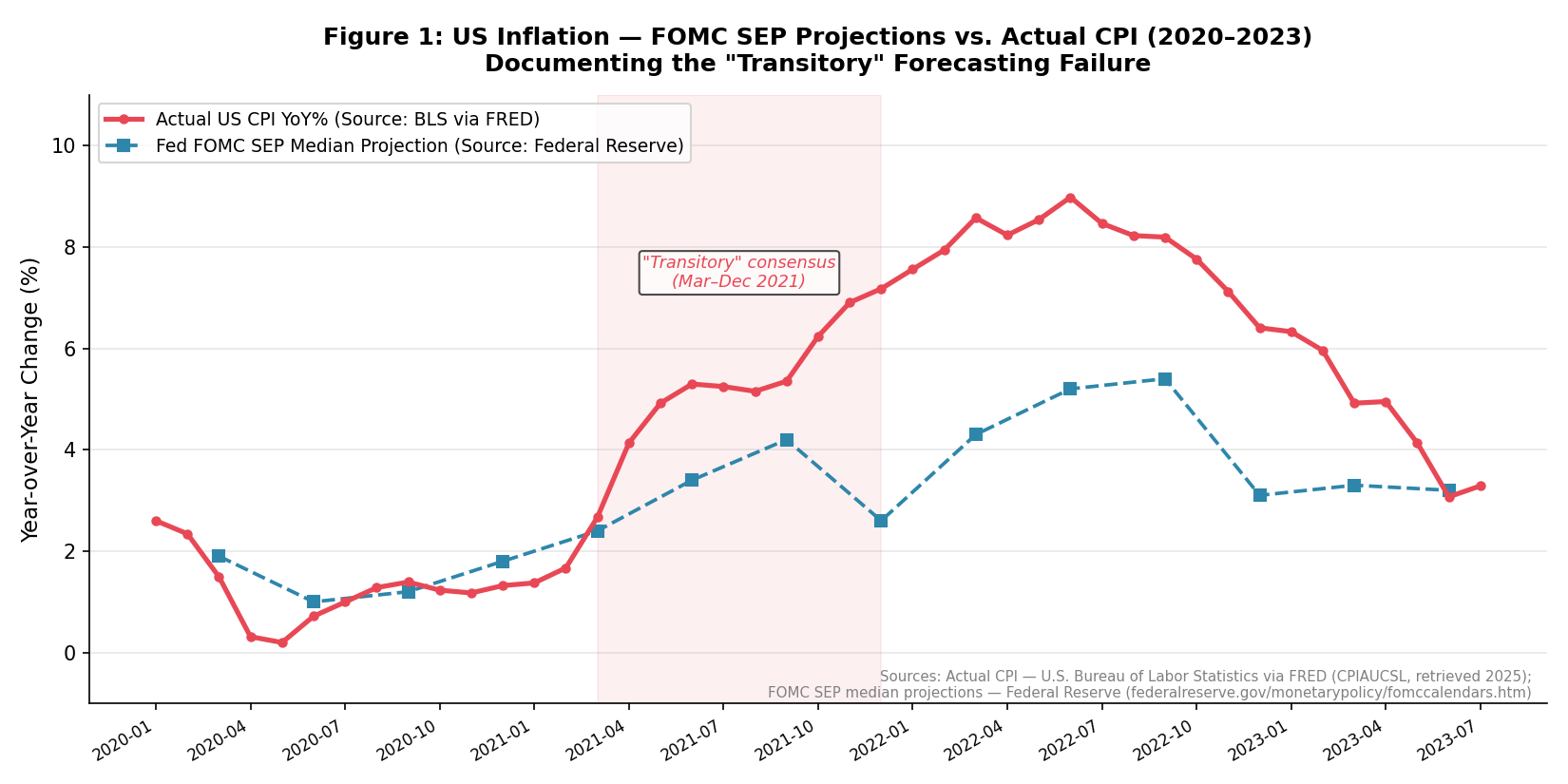
2021年至2023年期间,经济预测领域出现了显著且普遍的失误,尤其是在通货膨胀(inflation)方面。包括联邦储备系统(Federal Reserve)、欧洲中央银行(European Central Bank, ECB)和国际货币基金组织(International Monetary Fund, IMF)在内的主要机构,普遍认为COVID-19疫情及随后的供应链中断(supply chain disruptions)所导致的通胀飙升将是“暂时性的”(transitory)(Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。然而,这一共识被证明严重不准确,导致政策响应滞后并引发了重大的经济反响。这一事件并非孤立,而是经济分析长期以来系统性预测错误中的一个突出近期案例。从未能预见2008年全球金融危机,到国内生产总值(GDP)预测中持续存在的偏差,经济预测的记录常常揭示出一种无法用不可预测的外生冲击(exogenous shocks)简单解释的不准确模式。
这种反复出现的预测失误模式引发了一个关键的探究:为何拥有精湛技能、配备复杂模型和海量数据的经济学家,会以可预测的方式持续“犯错”?本文提出,这些系统性错误很大程度上不仅归因于模型局限性或固有的经济复杂性,更在于影响人类判断的认知偏差(cognitive biases)的普遍影响(Ezenwaka & Zharmagambetov, 2025; Theodossiou, 2020; Kyfyak & Bilak, 2025)。行为经济学(behavioral economics)已广泛记录了心理倾向(psychological predispositions)如何导致包括专家在内的个体偏离理性决策(rational decision-making)(Benjamin, 2019; Baron, 2014; Chen, 2024; Wang, 2025)。这些偏差,从过度自信(overconfidence)到锚定效应(anchoring)和羊群效应(herding),不仅是个体特质,还可能在预测过程中制度化,导致集体盲点和错误强化。
人工智能(Artificial Intelligence, AI)和机器学习(machine learning, ML)的进步为解决这些根深蒂固的挑战提供了新的机遇。与人类预测者不同,AI模型本质上不受过度自信或声誉担忧等心理偏差的影响(Manakhova & Makovskaya, 2025)。尽管AI系统有其自身的偏差来源,通常源于训练数据(training data)或模型选择(model selection)(Bini et al., 2026),但其计算客观性(computational objectivity)为纠正人类认知扭曲提供了潜在的视角。因此,问题在于:AI,特别是通过其分析能力和无偏处理能力,能否作为一种有效的去偏差机制(debiasing mechanism),以提高经济预测的准确性和可靠性?
本文旨在对这些关键问题进行系统分析。本研究的问题是双重的:哪些认知机制解释了经济预测中观察到的系统性错误,以及AI能否通过其独特能力有效纠正或缓解这些偏差?
本文的贡献是多方面的。首先,本文综合了大量文献,证明了经济预测失败在各个经济领域的系统性,并将其明确地与公认的认知偏差联系起来。这种整合弥合了预测错误的实证观察与行为经济学理论基础之间的鸿沟。其次,本文批判性地回顾了AI和机器学习在经济预测中表现的新兴证据,将其与人类专家的表现进行比较,并强调了AI的独特优势。最后,本文提出了一个人机协作(human-AI collaboration)的概念框架,概述了如何战略性地部署AI以对抗特定的认知偏差,从而增强经济预测的稳健性(robustness)和准确性。通过连接行为经济学预测和AI应用这两个截然不同但日益相关的文献领域,本文为在日益复杂和不确定的世界中改进经济决策的基础过程提供了见解。最终目标是超越简单地识别错误,提出可行的策略以实现更可靠的经济预见。
2. 经济学家预测失败的剖析:历史证据
经济预测(economic forecasting)尽管在指导政策和投资方面发挥着关键作用,但其存在显著且系统性错误的记录。这些失败并非随机发生,而是常常表现出可预测的模式,这表明其根本原因超越了单纯的内在不确定性。审视这些历史事件揭示了预测对超越个体预测者或特定方法论的偏差(biases)的持续脆弱性。
2.1 宏观经济预测的过往记录
国际组织和各国中央银行是宏观经济预测(macroeconomic forecasts)的主要生产者,然而它们的过往记录(track records)经常显示出与实际结果的系统性偏差(systematic deviations)。例如,国际货币基金组织(International Monetary Fund, IMF)的《世界经济展望》(World Economic Economic Outlook, WEO)预测被发现表现出持续的乐观偏差(optimism bias)(Aktuğ, 2025)。这种过度预测增长和低估衰退的倾向在不同国家和时期反复出现,表明这是一个系统性而非偶发性问题。
近期记忆中最显著的失败之一是,几乎所有主流经济学家和机构都未能预测到2008年全球金融危机(global financial crisis)(Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。尽管住房市场和复杂金融工具中累积的压力迹象日益明显,但共识观点(consensus view)在危机全面爆发之前仍基本保持乐观。这种集体盲点(collective blind spot)凸显了在识别和充分权衡新兴风险方面的重大系统性失败,这可能指向模型承诺(model commitment)和行业内羊群行为(herding behavior)的结合。
最近,2021-2023年的通货膨胀事件(inflation episode)是一个普遍预测灾难的鲜明例证。在COVID-19大流行期间,史无前例的财政和货币刺激以及供应链中断之后,全球通货膨胀飙升。然而,包括美联储(Federal Reserve)和欧洲中央银行(European Central Bank)以及国际货币基金组织在内的主要中央银行普遍认为,这种通货膨胀将是“暂时性的”(“transitory”)(Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。这一判断被证明是根本错误的,导致了长期的高通货膨胀和随后的激进货币政策紧缩(aggressive monetary policy tightening)。“暂时性”叙事(“transitory” narrative)在机构沟通中根深蒂固,尽管有越来越多的经验证据(empirical evidence)与之相悖,但它仍持续了很长一段时间,这表明不愿更新先验知识(priors)和潜在的叙事偏差(narrative bias)。
除了这些备受关注的事件之外,关于GDP预测误差的研究持续揭示了诸如顺周期性(pro-cyclicality)和羊群行为等模式。预测者在经济繁荣时期倾向于过度乐观,而在经济衰退时期则过度悲观,从而加剧了经济周期(economic cycle)的感知波动性。此外,有证据表明,预测会趋向于共识,即使个体信息可能表明存在分歧,这表明了声誉担忧(reputational concerns)和羊群行为(Felix, 2020)。McKenzie (2011) 提供了关于经济预测中平均绝对百分比误差(mean absolute percentage error)和偏差的见解,强调了系统性误差的持续存在。
2.2 金融市场预测
金融市场预测(financial market forecasting),特别是关于公司收益(corporate earnings)和资产价格(asset prices)的预测,也表现出系统性偏差。分析师预测(analyst forecasts)是投资者重要的输入信息,但它们经常以乐观为特征。研究持续记录了收益预测中的向上偏差(upward bias),即分析师倾向于高估未来的公司收益(Nardi, 2021)。这种乐观并非随机;它通常归因于多种因素,包括职业激励(career incentives)、管理层压力以及过度自信(overconfidence)等认知偏差(cognitive biases)(Hribar & Yang, 2011)。Nardi (2021) 特别强调了认知偏差和财务因素对分析师预测准确性的影响。
收益预测误差的系统性性质对市场效率(market efficiency)和投资决策(investment decisions)具有重要影响。当分析师持续高估未来业绩时,可能导致证券定价错误(mispricing of securities)和次优资本配置(suboptimal capital allocation)。此外,这些预测的修正常常表现出锚定效应(anchoring),即初始预测严重影响后续调整,导致即使面对新信息也更新不足(Aggarwal, 2022; Murhadi, 2025)。这种现象不仅限于个体分析师,在整个金融行业中都可以观察到,从而导致市场预期中的集体错误。
2.3 中央银行预测
中央银行肩负着物价稳定(price stability)和充分就业(full employment)的使命,其发布的经济预测(economic projections)具有高度影响力。然而,即使这些拥有大量资源和专业知识的机构也未能幸免于系统性预测误差。美联储的“点阵图”(“dot plot”),代表了联邦公开市场委员会(Federal Open Market Committee, FOMC)成员对联邦基金利率(federal funds rate)的个体预测,经常与实际利率路径存在分歧。这种分歧可归因于不断变化的经济状况,但也归因于个体和集体判断中的偏差。
除了利率预测之外,中央银行对通货膨胀和失业率的预测也显示出系统性偏差。例如,在2021-2023年的“暂时性”通货膨胀辩论中,美联储和欧洲中央银行持续低估了通货膨胀压力的持续性和幅度,导致政策响应比最初预测的延迟且更具侵略性(Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。同样,失业率预测在经济扩张期间可能表现出乐观倾向,而在经济收缩期间则表现出悲观倾向。中央银行预测中的这些系统性误差可能损害其信誉(credibility)并使有效的预期管理(forward guidance)复杂化,从而影响市场预期和经济稳定。这些误差在不同机构和经济指标中持续存在,强调了理解其背后认知机制(cognitive mechanisms)的必要性。
3. Cognitive Mechanisms: Why Economists Make Systematic Errors
预测误差在不同经济领域中表现出的一致性和系统性特征表明,它们并非简单的随机偏差,而是根植于人类认知 (cognition) 和行为的基本层面。行为经济学为理解这些认知偏差 (cognitive biases) 提供了一个稳健的框架,这些偏差能够显著影响包括经济学家在内的受过高等训练的专业人士的判断 (Benjamin, 2019; Baron, 2014; Ezenwaka & Zharmagambetov, 2025; Kyfyak & Bilak, 2025)。
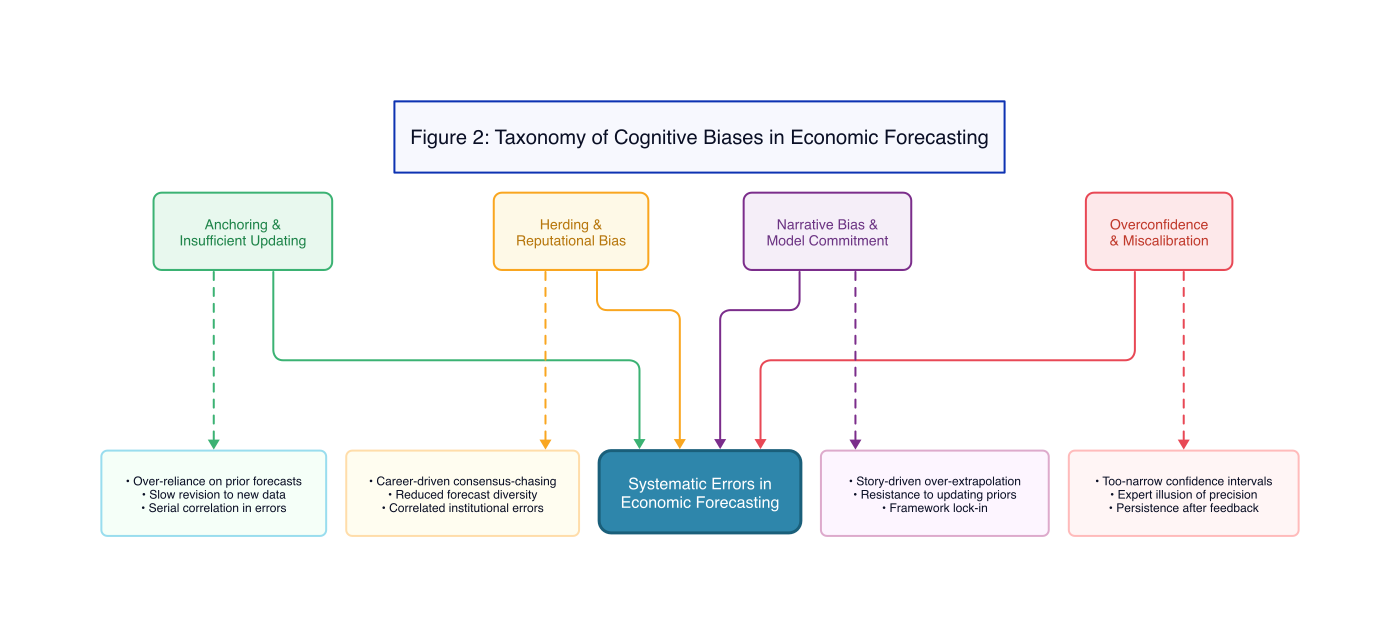
3.1 Overconfidence and Miscalibration
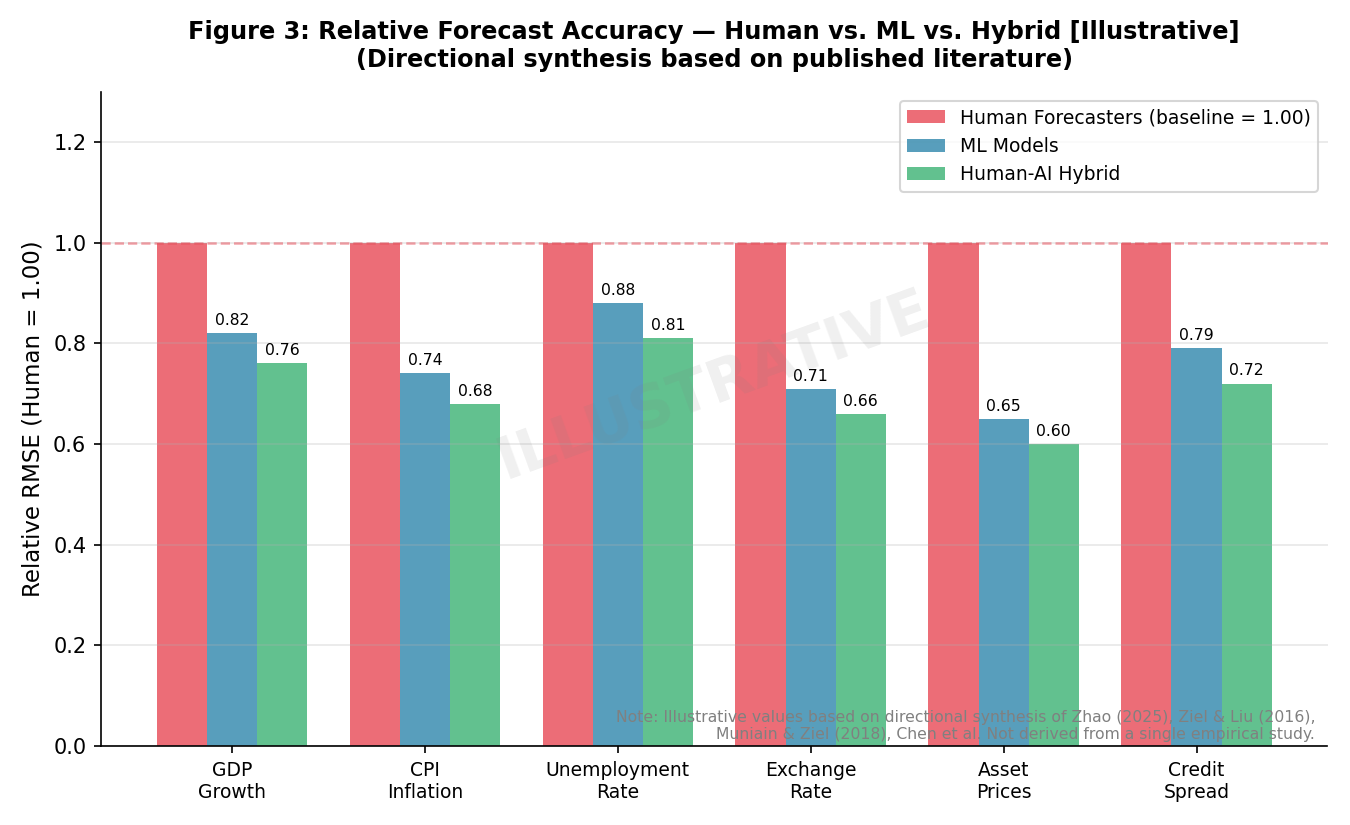
过度自信 (overconfidence) 是被研究最充分的认知偏差之一,它影响着包括经济学家和金融分析师在内的各行各业的个体 (Soll, 1996; Arkes, 2001; Hribar & Yang, 2011; Murhadi, 2025)。它以多种方式表现出来:高估自身能力、相对于他人高估自身表现,以及对自身信念的过度精确 (Fischer, 1982; Berg & Rietz, 2019)。在经济预测中,过度自信常表现为校准不良 (miscalibration),即预测者为其估计值设定过窄的预测区间 (prediction intervals),这表明其确定性程度高于实际结果所能证明的水平 (Soll, 1996; Adam et al., 2025)。对预测区间的各项研究持续表明,实际结果超出预测范围的频率高于其所宣称的置信水平。
经济学领域中专家的这种过度自信与其他领域相比是类似的,甚至有时更为显著 (Cassam, 2017)。例如,首席执行官 (CEO) 在其管理预测中也表现出过度自信 (Hribar & Yang, 2011)。M6 金融竞赛提供了避免过度自信的方法 (Makridakis et al., 2025)。其影响是深远的:过度自信的经济学家可能会低估其预测所固有的真实不确定性,从而导致基于夸大精确性和稳健性感的政策制定。这可能导致对不断变化的情况调整滞后,正如最初的“暂时性”通胀叙事所观察到的那样,对快速解决的信念可能因对潜在经济动态的过度自信评估而得到强化。锚定效应 (anchoring) 与过度自信之间的关联也得到了探讨,表明锚定效应可能导致估计中的过度自信 (Heywood-Smith et al., 2008; Czerwonka, 2017)。
3.2 Anchoring and Insufficient Updating
锚定偏差 (anchoring bias) 指的是个体在做出后续判断时,过度依赖初始信息(即“锚”),即使该信息不相关 (Block & Harper, 1991; Murata & Moriwaka, 2019; Murhadi, 2025)。在经济预测中,先前的预测,无论是预测者自身的还是其他有影响力的机构的预测,都可以作为强有力的锚 (Aggarwal, 2022; Bürgi, 2023; Felix, 2020; Murhadi, 2025)。这导致了更新不足 (insufficient updating),即后续的预测修正不成比例地受到初始锚的影响,而非充分整合新信息 (Bürgi, 2023)。
来自预测修正模式的实证证据支持了这一点。例如,分析师的盈利预测倾向于锚定于先前的预测,导致对新数据的调整缓慢 (Aggarwal, 2022)。类似地,宏观经济预测,如国内生产总值 (GDP) 或通胀预测,即使在发生重大经济转变时,也常表现出渐进式的调整。“暂时性”通胀事件提供了一个实质性案例:最初将通胀评估为暂时性的观点成为一个锚,使得预测者即使在通胀压力扩大并持续存在时,也难以迅速调整其展望 (Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。这种锚定效应可能导致宏观经济预期中的“过度反应”,即由于先前锚的影响,初始冲击被低估或高估 (Bordalo, 2020; Shleifer, 2025; Kelly, 2024)。
3.3 Herding and Reputational Bias
经济学家与其他专业人士一样,在社会和制度环境中运作,这些环境可能助长羊群行为 (herding behavior) (Felix, 2020; Murhadi, 2025)。羊群行为发生在个体将其判断与感知到的共识保持一致时,即使他们的私人信息表明不同的结论。这通常是由声誉考量和职业激励驱动的:与共识显著偏离且犯错,可能比与大多数人一起犯错对职业造成的损害更大 (Felix, 2020)。
羊群行为的证据在调查预测中普遍存在,例如专业预测者调查 (Survey of Professional Forecasters, SPF) 或蓝筹经济指标 (Blue Chip Economic Indicators)。这些调查常显示预测的聚集,表明个体预测者可能将其预测调整至平均值以避免突出。这种趋势可能抑制多样化的观点,并导致集体盲点,正如未能预测 2008 年金融危机或对“暂时性”通胀的普遍共识所见。当主导性叙事或预测从一个领先机构出现时,其他人可能会倾向于它,这不一定是由于独立验证,而是为了降低职业风险。这可能导致一个自我强化的循环,其中初始偏差通过集体从众行为被放大。
3.4 Narrative Bias and Model Commitment
经济学家常依赖连贯的叙事或理论模型来理解和预测经济现象。虽然这对于构建思维至关重要,但这种依赖可能成为偏差的来源。叙事偏差 (narrative bias) 涉及将新信息纳入现有故事或框架,即使这需要选择性解释或淡化矛盾证据 (Petticrew et al., 2020)。这可能导致对更新先验 (priors) 的抵制,特别是当新数据挑战一个根深蒂固的模型或叙事时。
“暂时性”通胀叙事是一个典型例子。疫情后通胀的初始理论框架侧重于暂时性供给冲击和基数效应。随着通胀扩大和工资压力出现,与这一叙事相矛盾,许多预测者难以放弃其初始模型承诺 (model commitment),继续通过“暂时性”视角解释新数据 (Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。当一个模型在过去取得成功或在行业内被广泛接受时,这种对更新的抵制可能尤为强烈。过度依赖特定的理论框架,即使它们在面对新情况时显得不足,也可能阻碍预测者考虑可能提供更准确图景的替代解释或模型。
3.5 Institutional and Incentive Factors
除了个体认知偏差之外,预测发生的制度背景也可能显著放大或减轻这些偏差。预测机构(如中央银行或国际组织)的政治经济学可能引入微妙地扭曲预测的激励机制。例如,中央银行可能面临呈现乐观前景以维持市场信心的压力,或者国际机构可能被激励预测稳定以鼓励投资。
这些制度压力可以强化乐观主义或羊群行为等偏差。这些组织内的预测者可能无意识或有意识地调整其预测,以符合机构的感知立场或避免内部异议。这可能创造一个难以挑战共识的环境,即使数据另有表明。许多机构预测的集体性质,常通过委员会或汇总输入产生,也可能分散个体责任,使得偏差更容易不受控制地持续存在。因此,理解经济学家为何会犯系统性错误,需要一个整合个体认知倾向与他们所运作的更广泛制度和激励结构的整体视角 (Bonardi et al., 2024)。
4. 人工智能替代方案:机器性能的现有证据
人类在经济预测(economic forecasting)中认知偏差(cognitive biases)的持续性和系统性,促使人们对人工智能(Artificial Intelligence, AI)和机器学习(machine learning, ML)作为替代或补充预测工具的潜力产生了日益增长的兴趣。其基本前提是,AI凭借其计算本质(computational nature),能够固有地免疫于困扰人类判断的许多心理倾向(psychological predispositions)(Manakhova & Makovskaya, 2025)。
4.1 机器学习与人类预测者:实证比较
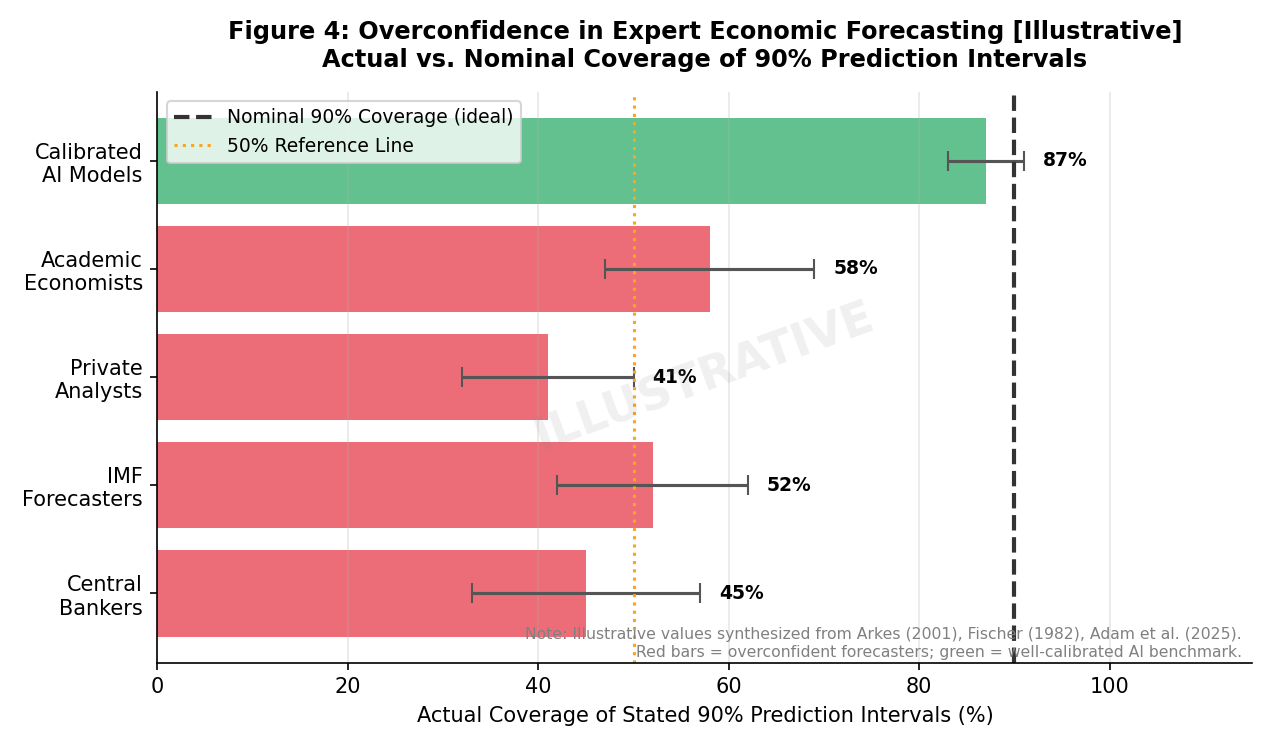
越来越多的实证研究(empirical studies)直接比较了ML模型与专业人类预测者在各种经济和金融领域的预测性能(forecasting performance)。这些比较通常揭示出细致入微的结果:AI在特定情境中表现出卓越的性能,而人类在其他情境中则保持优势。
在以高维数据(high-dimensional data)、复杂非线性关系(non-linear relationships)和快速数据生成为特征的领域,ML模型经常超越人类专家。例如,在电力价格或负荷(load)的短期预测(short-term forecasting)中,Lasso估计(Lasso estimation)和分位数回归(quantile regression)等复杂的ML算法已显示出高准确性(Ziel, 2016; Ziel, 2018; Muniain & Ziel, 2018; Kath & Ziel, 2018)。采用深度泊松混合(deep Poisson mixtures)的概率分层预测(probabilistic hierarchical forecasting)也在复杂时间序列(time series)中展现出先进能力(Olivares et al., 2021)。这些模型能够识别出人类分析师可能因认知负荷(cognitive load)或偏差而遗漏或误解的细微模式和关联。比较各种预测方法(包括ML)的研究通常强调算法方法在误差指标(error metrics)方面的卓越性能(表1:不同预测方法的预测误差比较)。
Uniejewski和Maciejowska (2022) 提出了LASSO主成分平均法(LASSO Principal Component Averaging)作为点预测池化(point forecast pooling)的全自动化方法,进一步说明了ML在预测聚合(forecast aggregation)中的潜力。
然而,AI的优越性并非普遍存在。在需要情境理解(contextual understanding)、定性判断(qualitative judgment)、整合新颖非结构化信息(unstructured information),或在结构性断裂(structural breaks)和前所未有事件(unprecedented events)期间进行预测的情况下,人类预测者通常仍占优势。例如,在极端经济动荡(economic upheaval)或政策制度转变(policy regime shifts)时期,历史数据模式可能不再适用,人类直觉(human intuition)和定性推理(qualitative reasoning)可能至关重要。即便在这些复杂情境中,结合人类专业知识与ML数据处理能力(data processing power)的混合方法(hybrid approaches)也正日益被探索(Zhao, 2025)。
4.2 AI对认知偏差的免疫性
AI在预测中作用的最实质性论据之一是其固有地免疫于困扰人类判断的认知偏差(Manakhova & Makovskaya, 2025)。ML模型从根本上不会经历过度自信(overconfidence)、锚定(anchoring)、羊群效应(herding)或声誉考量(reputational concerns)(Bini et al., 2026)。
- 无锚定效应: AI模型处理新数据时,不会像人类那样在心理上受制于先前的预测或初始估计(Bini et al., 2026)。尽管模型可以拥有过去状态的“记忆”,但其更新机制是算法性的(algorithmic),而非心理性的。这意味着它们在面对新信息时,不太可能表现出更新不足(insufficient updating)——这是一种常见的人类缺陷(Bürgi, 2023)。
- 无羊群效应: AI算法根据其编程逻辑和训练数据进行预测,而非根据其他模型或人类专家的共识观点(consensus view)(Bini et al., 2026)。它们没有职业考量(career concerns)或声誉激励(reputational incentives)去从众,从而避免了羊群效应可能造成的集体盲点(collective blind spots)。
- 无过度自信: 尽管AI模型可能会输出一个置信区间(confidence interval),但这是一种源自其内部计算和不确定性估计(uncertainty estimation)的统计度量(statistical measure),而非过度精确(overprecision)的心理状态(psychological state)(Soll, 1996; Arkes, 2001)。概率预测(probabilistic forecasting)等先进ML技术(Damato et al., 2025; Ziel, 2018; Olivares et al., 2021)旨在明确量化不确定性,提供比人类判断中常观察到的更校准的预测准确性(prediction accuracy)评估(Soll, 1996; Fischer, 1982)。
然而,承认AI也存在其自身的一系列偏差至关重要(Bini et al., 2026)。这些偏差通常并非人类意义上的认知偏差,而是源于用于训练的数据(例如,历史偏差、选择偏差)、模型架构(model architecture)的选择或正在优化的目标函数(objective function)(Bini et al., 2026)。例如,如果训练数据(training data)反映了过去的人类偏差或结构性不平等,AI模型可能会在其预测中延续甚至放大这些偏差。同样,一个在稳定经济时期(stable economic period)数据上训练的模型,在面对其训练集中未出现的新型危机情景(novel crisis scenario)时,可能会表现不佳并展现出“偏差”。理解和缓解(mitigating)这些算法偏差(algorithmic biases)是当前研究的一个关键领域(Bini et al., 2026)。
4.3 LLM在经济分析中的能力
大型语言模型(large language models, LLMs)的出现为AI在经济分析中的潜力引入了另一个维度。LLMs通过对海量文本数据(text data)进行训练,能够处理和综合(synthesize)复杂的定性信息(qualitative information),生成叙事(generate narratives),并执行模仿人类认知过程的推理任务(reasoning tasks)(Manakhova & Makovskaya, 2025)。这种能力延伸到经济分析领域,LLMs可以解读经济报告(economic reports),识别关键趋势(key trends),总结复杂论点(summarize complex arguments),甚至根据文本数据(textual data)和定性指标(qualitative indicators)生成经济预测。
研究正开始探索LLM的经济推理能力(economic reasoning ability),评估它们理解经济概念、应用理论框架(theoretical frameworks)和做出明智判断(informed judgments)的能力。尽管LLMs可以生成连贯(coherent)且看似富有洞察力的分析(insightful analyses),但其性能高度依赖于训练数据的质量和广度。然而,一个关键的担忧是“AI的行为经济学”(Behavioral Economics of AI)(Bini et al., 2026)。LLMs尽管具有计算性质,但可能表现出与人类认知偏差相似的偏差,特别是那些与其训练数据相关的偏差。例如,如果一个LLM在一个由特定经济学派(economic school of thought)或特定叙事(narrative)主导的语料库(corpus)上进行训练,它可能会在其自身的分析中无意中延续(inadvertently perpetuate)这种偏差(Bini et al., 2026)。它们还可能“幻觉”(hallucinate)或生成看似合理但错误的信息。因此,尽管LLMs为处理定性经济信息和生成复杂分析提供了令人兴奋的前景,但必须批判性地评估其输出,并且必须理解和解决其固有的、源于训练数据和算法设计(algorithmic design)的偏差(Bini et al., 2026)。
5. 人工智能与人类协作的必要性 (The Case for Human-AI Collaboration)
鉴于人类经济预测中固有的系统性偏差以及人工智能 (AI) 独特的优势和劣势,人工智能与人类协作而非完全替代的实质性必要性日益凸显。这种方法利用了人类直觉和算法精度 (algorithmic precision) 的互补能力,旨在创建一个更准确、更稳健且不易受认知缺陷 (cognitive pitfalls) 影响的预测生态系统。
5.1 互补性框架 (Complementarity Framework)
人工智能与人类在经济预测中协作的核心在于一个互补性框架:人类提供背景信息、判断力以及适应新情况的能力,而人工智能则提供校准 (calibration)、数据处理能力以及对特定认知偏差的免疫力 (Watkins & Human, 2022)。这种协同作用 (synergy) 使两者能够相互弥补各自的局限性。
- 人类提供背景信息和定性洞察 (qualitative insights): 经济学家拥有深厚的制度知识 (institutional knowledge)、对政治和社会动态的理解,以及解释人工智能难以完全掌握的定性信息的能力。他们能够识别结构性断裂 (structural breaks)、预测政策转变,并理解经济现象背后的“为什么”,这对于解释人工智能输出和设置适当的模型参数至关重要。
- 人工智能提供校准和数据驱动的洞察 (data-driven insights): 人工智能模型能够处理海量数据集 (datasets)、识别复杂的非线性关系 (non-linear relationships),并生成具有严格统计校准的预测,包括稳健的不确定性量化 (uncertainty quantification) (Damato et al., 2025; Ziel, 2018; Olivares et al., 2021)。它们可以提供客观的、数据驱动的基准 (benchmarks),从而挑战人类直觉并揭示偏差。
混合预测方法 (hybrid forecasting approaches) 的证据支持了这种互补性。研究表明,将人类判断与统计或机器学习 (machine learning) 模型相结合,通常比单独使用任何一种方法都能产生更优越的性能。
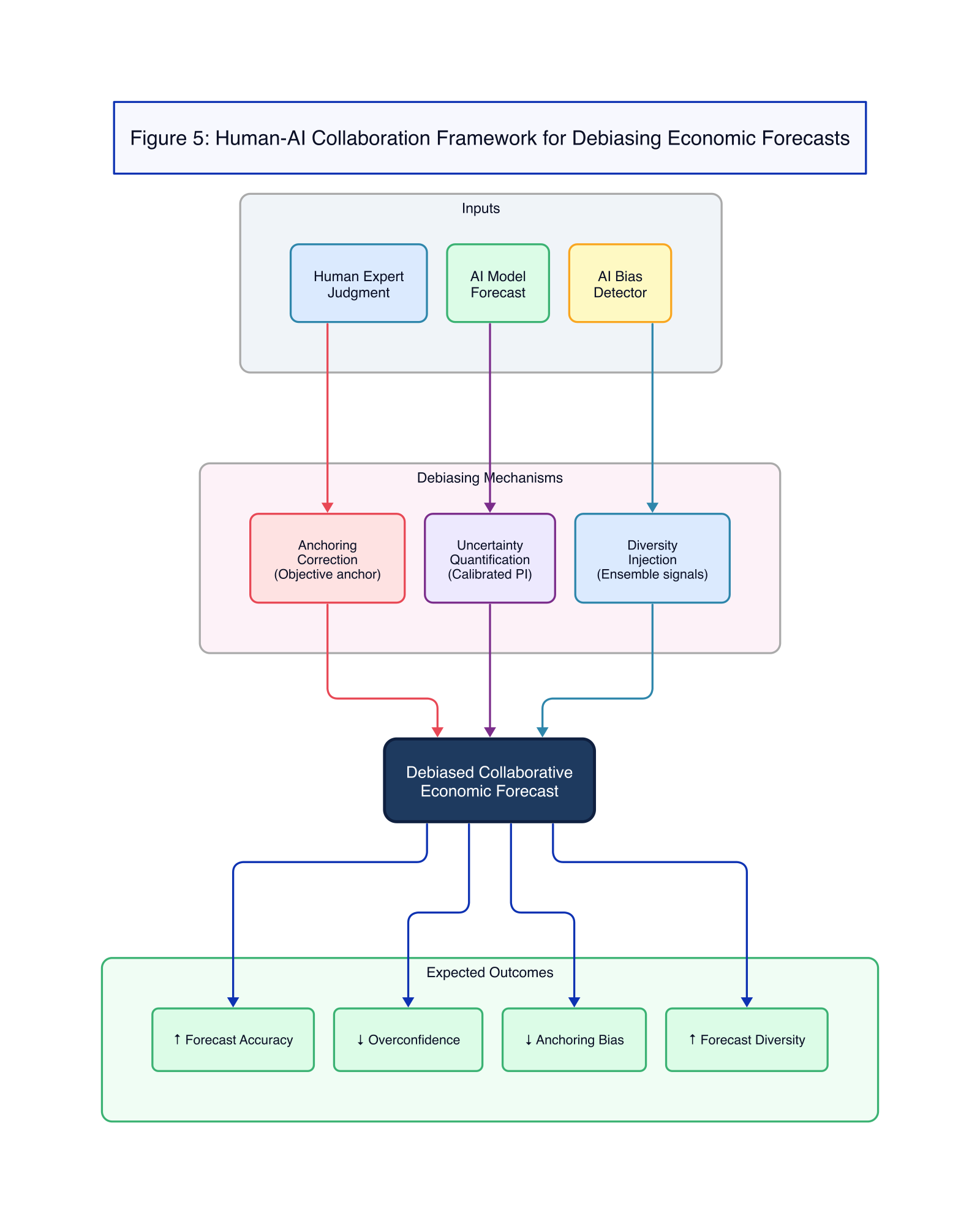
当模型难以应对前所未有的事件时,人类元素可以完善模型输入、解释输出并进行干预,而人工智能组件则可以提供一致、无偏的基线 (baseline),并识别超出人类认知能力范围的模式。
5.2 去偏差机制 (Debiasing Mechanisms)
人工智能工具可以作为强大的去偏差机制,系统性地抵消前述的认知偏差:
- 对抗锚定效应 (Counteracting Anchoring): 人工智能可以提供独立于人类先前预测的客观、数据驱动的参考点 (Bini et al., 2026)。通过呈现纯粹基于数据和模型逻辑得出的预测,人工智能可以作为一种“助推器” (nudge),防止人类预测者过度锚定于过时或有偏的初始估计 (Petticrew et al., 2020)。例如,人工智能模型可以根据最新数据生成预测,而不将任何历史人类预测作为输入,迫使人类分析师面对一个可能不同的现实,并减少其自身先前预测的影响 (Aggarwal, 2022; Bürgi, 2023)。
- 对抗过度自信 (Counteracting Overconfidence): 人工智能擅长不确定性量化。概率预测模型 (probabilistic forecasting models) 可以生成可能的完整结果分布 (full distributions of possible outcomes),明确说明各种情景的可能性 (Damato et al., 2025; Ziel, 2018; Olivares et al., 2021)。向人类预测者呈现这些经过校准的不确定性估计,可以直接挑战他们过度精确 (overprecision) 和校准不良 (miscalibration) 的倾向 (Soll, 1996; Arkes, 2001)。通过展示广泛的合理结果范围,人工智能可以鼓励对未来经济状况进行更审慎和现实的评估,从而缓解“过度自信综合症” (overconfidence syndrome) (Fischer, 1982)。
- 对抗羊群效应 (Counteracting Herding): 人工智能可以生成多样化的模型集成 (model ensembles),每个集成都在不同的数据子集上训练或使用不同的算法,从而产生一系列独立的预测 (Uniejewski & Maciejowska, 2022)。这种集成方法可以打破人类驱动的共识预测的同质性。通过呈现更广泛的合理结果范围,人工智能可以减轻个体人类预测者遵从单一共识的压力,从而促进更独立和多样化的视角。这有助于防止因羊群行为而产生的集体盲点 (Felix, 2020)。
5.3 实施证据 (Implementation Evidence)
尽管该领域仍在发展,但已有一些新兴案例表明人工智能与人类协作显著提高了预测准确性。例如,在天气预报中,将复杂的数值模型 (numerical models)(一种人工智能形式)与人类专家判断相结合,已使预测结果显著优于纯粹由人类或纯粹由模型驱动的预测。类似模式也开始出现在经济应用中。
例如,一些金融机构正在使用机器学习 (ML) 模型生成初始盈利预测,然后由人类分析师审查和调整,他们会纳入定性信息或市场情报 (market intelligence)。这种混合方法在减少纯粹由人类生成的金融预测中常见的系统性乐观偏差 (systematic optimism bias) 方面显示出前景 (Nardi, 2021)。中央银行也在探索使用人工智能生成替代情景 (alternative scenarios) 或识别传统计量经济学模型 (econometric models) 可能遗漏的数据异常 (anomalies),为其人类推导的预测提供额外的审查层。
有效的人工智能与人类协作的关键条件包括:
- 明确分工 (Clear Division of Labor): 明确人工智能处理数据处理和校准,而人类则专注于情境解释和战略判断的角色。
- 信任与透明度 (Trust and Transparency): 人类预测者必须信任人工智能的输出,这需要模型设计的透明度以及对其优势和局限性的清晰沟通。
- 持续学习与反馈 (Continuous Learning and Feedback): 人类和人工智能组件都应不断从过去的错误中学习,通过反馈循环 (feedback loops) 改进模型性能和人类去偏差策略。
- 用户友好界面 (User-Friendly Interfaces): 人工智能工具必须设计成易于人类用户解释和操作,避免阻碍信任和有效集成的“黑箱”方法 (black-box approaches)。
通过战略性地将人工智能作为去偏差代理 (debiasing agent) 进行集成,经济预测可以迈向一个未来,其中预测不仅更准确,而且对人类判断固有的认知局限性更具鲁棒性 (robustness)。
6. 政策启示与制度设计
对经济预测中认知偏差(cognitive biases)的系统性理解以及人工智能(AI)在去偏差(debiasing)方面的潜力,对处于经济预测和决策前沿的机构具有重要的政策启示。改革制度设计和预测流程以纳入这些见解,可以带来更具韧性的经济和更有效的政策响应。
对于中央银行而言,其影响尤为显著。2021-2023年“暂时性”(transitory)通胀的错误凸显了根深蒂固的叙事和不充分的更新如何导致政策行动的延迟,并最终造成更大的破坏(Counts, 2024; University of California, Berkeley Haas School of Business, 2024)。中央银行应考虑将AI驱动的预测模型作为独立的“魔鬼代言人”(devil’s advocate)整合到其预测流程中。这些模型不受人类认知偏差的影响,可以提供替代情景(alternative scenarios)和经过校准的不确定性估计(calibrated uncertainty estimates),从而挑战人类预测者的共识观点(Bini et al., 2026)。这可能包括:
- 强制要求AI生成概率预测(probabilistic forecasts): 要求AI模型为关键经济变量(通货膨胀、失业率、GDP)生成明确的概率分布,有助于纠正人类预测者的过度自信(overconfidence)和校准不当(miscalibration)(Damato et al., 2025; Ziel, 2018; Olivares et al., 2021)。
- 利用AI进行异常检测(anomaly detection): AI可以识别数据模式中可能预示新兴风险或偏离基线预测(baseline forecasts)的细微变化,而受锚定效应(anchoring)影响的人类分析师可能会忽视这些变化。
- 多样化预测输入: 通过纳入更广泛的AI驱动模型,超越传统的计量经济学模型(econometric models),可以通过提供更多样化的初始预测来减少人类预测者之间的羊群效应(herding)。
对于**国际货币基金组织(IMF)和世界银行(World Bank)**等提供全球经济展望和政策建议的机构而言,解决乐观偏差(optimism bias)和羊群效应至关重要(Aktuğ, 2025)。制度改革可以包括:
- 建立独立的AI预测部门: 这些部门将具有一定程度的自主权,提供明确设计为不受可能导致乐观偏差的机构或政治压力影响的预测。
- 利用AI实施“红队演练”(red teaming): 使用AI模型通过模拟不利情景或识别共识预测中的潜在盲点来对人类预测进行压力测试(stress-test)。这有助于减轻2008年危机前出现的集体失败。
- 促进透明的不确定性沟通: AI量化不确定性的能力可以鼓励这些机构传达更现实的结果范围,而非可能助长虚假精确感的点估计(point estimates)。
在金融部门,分析师预测的乐观偏差和锚定偏差已得到充分证实(Nardi, 2021; Aggarwal, 2022),AI在提高市场效率和投资决策方面可以发挥关键作用:
- AI辅助的盈利估算: 投资银行和资产管理公司可以部署AI来生成初始的、无偏差的盈利预测,然后由分析师进行完善。这种混合方法可以减少人类分析师预测中观察到的系统性乐观偏差。
- 实时去偏差工具: AI驱动的仪表板可以通过将分析师的预测与客观基准进行比较或标记与数据驱动概率的偏差,来提醒分析师其自身预测中潜在的认知偏差。
- 增强风险管理: 通过提供更精确校准的概率预测,AI可以改进市场风险评估,帮助投资者做出更明智的决策,并可能减少行为偏差(behavioral biases)对投资组合构建(portfolio construction)的影响(Murhadi, 2025)。
人机协作(human-AI collaboration)的成功实施需要审慎的制度设计。这包括培养一种重视批判性自我反思并拥抱技术增强(technological augmentation)的文化,而非将AI视为威胁。针对经济学家和金融专业人士的培训项目将至关重要,以使他们掌握有效与AI输出互动和解释AI输出的技能。此外,健全的伦理准则和监管框架将是必要的,以解决AI驱动预测中与算法偏差(algorithmic bias)、数据隐私和问责制相关的问题。通过主动将AI整合为一种去偏差力量,经济机构可以迈向一个预测不仅更准确,而且更透明和值得信赖的未来,最终支持更好的经济治理和金融稳定。
7. 结论
经济预测中反复出现的失误,例如2021-2023年“暂时性”(transitory)通胀的共识以及2008年金融危机预警信号的遗漏,突出表明了一个根本性挑战:人类认知偏差(cognitive biases)系统性地扭曲了专家判断。本文系统分析了过度自信(overconfidence)、锚定效应(anchoring)、羊群效应(herding)和叙事偏差(narrative bias)等现象如何渗透到主要经济机构的预测过程中,从而导致可预测且往往代价高昂的错误。这些偏差并非随机产生,而是根植于人类决策的深层机制中,即使是训练有素的专业人士也难以幸免。
然而,人工智能(Artificial Intelligence, AI)的快速发展为缓解这些持续存在的挑战提供了一条有前景的途径。AI模型凭借其计算特性,本质上能够免受影响人类预测者的许多心理偏差的影响。尽管AI自身也存在偏差来源,主要源于训练数据(training data)和模型设计(model design),但经验证据表明,机器学习(machine learning)模型在特定预测任务中可以超越人类专家,尤其是在涉及复杂数据模式(complex data patterns)和严格不确定性量化(uncertainty quantification)的任务中。
最有效的策略并非用AI取代人类经济学家,而是促进稳健的人机协作(human-AI collaboration)。这种协同方法(synergistic approach)将人类专家的情境理解(contextual understanding)和适应性判断(adaptive judgment)与AI的无偏处理能力(unbiased processing power)和校准能力(calibration capabilities)相结合。通过充当去偏差机制(debiasing mechanism),AI可以提供客观的参考点以对抗锚定效应,提供经过校准的不确定性估计以缓解过度自信,并生成多样化的视角以减少羊群行为。在中央银行、国际组织和金融部门内部实施此类混合系统(hybrid systems),有望实现更准确、更稳健、更透明的经济预测。展望未来,将AI负责任且战略性地整合到预测过程中,并持续研究AI自身的偏差和伦理影响,对于增强经济预见性(economic foresight)和促进更稳定、更繁荣的经济至关重要。
参考文献
Aggarwal, R. (2022). Economic forecasts, anchoring bias (锚定偏差), and stock returns. DOI:
Aktuğ, E. (2025). An Evaluation of World Economic Outlook Forecasts: Any Evidence of Asymmetry? (世界经济展望预测评估:是否存在不对称性证据?) in: IMF Working Papers Volume 2025 Issue 031 (2025). DOI:
Arkes, H. R. (2001). Overconfidence in Judgmental Forecasting (判断性预测中的过度自信). DOI: 10.1007/978-0-306-47630-3_22
Baron, J. (2014). Heuristics and Biases (启发式与偏差). DOI: 10.1093/oxfordhb/9780199945474.013.0001
Benjamin, D. J. (2019). Errors in probabilistic reasoning and judgment biases (概率推理中的错误与判断偏差). DOI: 10.1016/bs.hesbe.2018.11.002
Berg, J. E., & Rietz, T. A. (2019). Longshots, overconfidence and efficiency on the Iowa Electronic Market (爱荷华电子市场中的冷门、过度自信与效率). DOI: 10.1016/j.ijforecast.2018.03.004
Bini, P., Cong, L. W., Huang, X., & Zhang, Y. (2026). Behavioral Economics of AI: LLM Biases and Corrections (人工智能的行为经济学:大型语言模型偏差与修正). DOI:
Block, R. A., & Harper, D. R. (1991). Overconfidence in estimation: Testing the anchoring-and-adjustment hypothesis (估计中的过度自信:检验锚定与调整假说). DOI: 10.1016/0749-5978(91)90048-x
Bonardi, J.-P., Sornette, D., & Danon, R. (2024). Behavioral Biases in Financial Decision Making : Implications for Accounting and Economic Forecasting (金融决策中的行为偏差:对会计与经济预测的影响). DOI: 10.70062/harmonieconomics.v1i2.31
Bordalo, P. (2020). Overreaction in Macroeconomic Expectations - American Economic Association (宏观经济预期中的过度反应 - 美国经济学会). DOI:
Bürgi, C. (2023). Overreaction Through Anchoring (通过锚定产生的过度反应). DOI:
Cassam, Q. (2017). Diagnostic error, overconfidence and self-knowledge (诊断错误、过度自信与自我认知). DOI: 10.1057/palcomms.2017.25
Chen, X., Pang, Y., & Zheng, G. (None). Macroeconomic Forecasting Using Genetic Programming Based Vector Error Correction Model (基于遗传规划的向量误差修正模型在宏观经济预测中的应用). DOI: 10.4018/978-1-61520-629-2.ch001
Chen, Y. (2024). An Overview of Behavioral Economics (行为经济学概述). DOI: 10.25236/ajbm.2024.060306
Counts, L. (2024). Why economic forecasts are so often wrong (经济预测为何频频出错). DOI:
Czerwonka, M. (2017). Anchoring and Overconfidence: The Influence of Culture and Cognitive Abilities (锚定与过度自信:文化与认知能力的影响). DOI: 10.1515/ijme-2017-0018
Damato, S., Azzimonti, D., & Corani, G. (2025). Forecasting intermittent time series with Gaussian Processes and Tweedie likelihood (使用高斯过程和Tweedie似然函数预测间歇时间序列). DOI:
Ezenwaka, H. P., & Zharmagambetov, Y. (2025). The Role of Behavioral Economics and Cognitive Bias (认知偏差) in Shaping the Accuracy of Foresight and Intelligence Analysis (行为经济学与认知偏差在塑造预见和情报分析准确性中的作用). DOI:
Felix, L. F. F. (2020). Predictable Biases in Macroeconomic Forecasts and Their Impact Across Asset Classes (宏观经济预测中的可预测偏差及其对各类资产的影响). DOI:
Filin, I. D., Andriyashenko, V. A., Kozenko, A. I., & Popenko, A. N. (2025). ECONOMIC EXPECTATIONS AND FORECASTING ERRORS: STATISTICAL ANALYSIS OF COGNITIVE BIASES (经济预期与预测误差:认知偏差的统计分析). DOI: 10.36871/ek.up.p.r.2025.12.03.001
Fischer, G. W. (1982). Scoring-rule feedback and the overconfidence syndrome in subjective probability forecasting (评分规则反馈与主观概率预测中的过度自信综合征). DOI: 10.1016/0030-5073(82)90250-1
Heywood-Smith, A. B., Welsh, M. B., & Begg, S. H. (2008). Cognitive Errors in Estimation: Does Anchoring Cause Overconfidence? (估计中的认知错误:锚定是否导致过度自信?). DOI: 10.2118/116612-ms
Hribar, P., & Yang, H. (2011). CEO Overconfidence and Management Forecasting (首席执行官过度自信与管理预测). DOI: 10.2139/ssrn.929731
Kath, C., & Ziel, F. (2018). The value of forecasts: Quantifying the economic gains of accurate quarter-hourly electricity price forecasts (预测的价值:量化准确的每刻钟电价预测所带来的经济收益). DOI:
Kelly, B. T. (2024). Behavioral Impulse Responses (行为脉冲响应). DOI:
Kyfyak, V., & Bilak, A. (2025). COGNITIVE BIASES AND THEIR IMPACT ON ECONOMIC DECISIONS (认知偏差及其对经济决策的影响). DOI: 10.32782/business-navigator.80-23
Makridakis, S., Spiliotis, E., & Michailidis, M. (2025). Avoiding overconfidence: Evidence from the M6 financial competition (避免过度自信:来自M6金融竞赛的证据). DOI: 10.1016/j.ijforecast.2024.10.001
Manakhova, I. V., & Makovskaya, A. M. (2025). Human and artifi cial intelligence in the discourse of behavioral economics (行为经济学语境下的人工智能). DOI: 10.55959/msu0130-0105-6-60-3-1
McKenzie, J. (2011). Mean absolute percentage error and bias in economic forecasting (经济预测中的平均绝对百分比误差与偏差). DOI: 10.1016/j.econlet.2011.08.010
Muniain, P., & Ziel, F. (2018). Probabilistic Forecasting in Day-Ahead Electricity Markets: Simulating Peak and Off-Peak Prices (日前电力市场中的概率预测:模拟峰谷电价). DOI:
Murata, A., & Moriwaka, M. (2019). Basic Study on Prevention of Human Error-Anchoring Bias in Relationship between Objective and Subjective Probability- (预防人为错误的基础研究——客观概率与主观概率关系中的锚定偏差). DOI: 10.54941/ahfe100184
Murhadi, W. (2025). The Effect of Overconfidence, Representative, Anchoring, and Availability Biases on Investment Decisions and Market Efficiency (过度自信、代表性偏差、锚定偏差和可得性偏差对投资决策和市场效率的影响). DOI: 10.24843/matrik:jmbk.2024.v18.i02.p03
Nardi, P. C. C. (2021). The Influence of Cognitive Biases and Financial Factors on Forecast Accuracy of Analysts (认知偏差和金融因素对分析师预测准确性的影响). DOI:
Olivares, K. G., Meetei, O. N., Ma, R., & Sahoo, N. (2021). Probabilistic Hierarchical Forecasting with Deep Poisson Mixtures (深度泊松混合模型的概率分层预测). DOI:
Petticrew, M., Maani, N., Pettigrew, L., & Van Schalkwyk, M. C. I. (2020). Dark Nudges and Sludge in Big Alcohol: Behavioral Economics, Cognitive Biases, and Alcohol Industry Corporate Social Responsibility (大型酒业中的“黑暗助推”与“污泥”:行为经济学、认知偏差与酒业企业社会责任). DOI: 10.1111/1468-0009.12475
Shleifer, A. (2025). Overreaction in Macroeconomic Expectations (宏观经济预期中的过度反应). DOI:
Soll, J. B. (1996). Determinants of Overconfidence and Miscalibration: The Roles of Random Error and Ecological Structure (过度自信与校准不良的决定因素:随机误差与生态结构的作用). DOI: 10.1006/obhd.1996.0011
Table 1: Comparison of forecasting error of different forecasting methods (表2:不同预测方法的预测误差比较). (None). DOI: 10.7717/peerjcs.1514/table-5
Theodossiou, P. (2020). Impact of Cognitive Biases on Forecasting Models (认知偏差对预测模型的影响). DOI:
Uniejewski, B., & Maciejowska, K. (2022). LASSO Principal Component Averaging — a fully automated approach for point forecast pooling (LASSO主成分平均法——一种完全自动化的点预测池化方法). DOI:
University of California, Berkeley Haas School of Business. (2024). Why Economic Forecasts Are So Often Wrong (经济预测为何频频出错). DOI:
Wang, X. (2025). Bounded Rationality (有限理性) and Cognitive Bias: A Meta-Synthetic Framework for Behavioral Economics (有限理性与认知偏差:行为经济学的元合成框架). DOI: 10.23977/infse.2025.060218
Watkins, R., & Human, S. (2022). Needs-aware Artificial Intelligence: AI that ‘serves [human] needs’ (需求感知人工智能:服务人类需求的AI). DOI:
Zhao, Y. (2025). Forecasting Follies: Machine Learning from Human Errors (预测失误:从人类错误中进行机器学习). DOI:
Ziel, F. (2016). Lasso estimation for GEFCom2014 probabilistic electric load forecasting (GEFCom2014概率电力负荷预测的Lasso估计). DOI:
Ziel, F. (2018). Quantile Regression for Qualifying Match of GEFCom2017 Probabilistic Load Forecasting (GEFCom2017概率负荷预测资格赛的分位数回归). DOI: